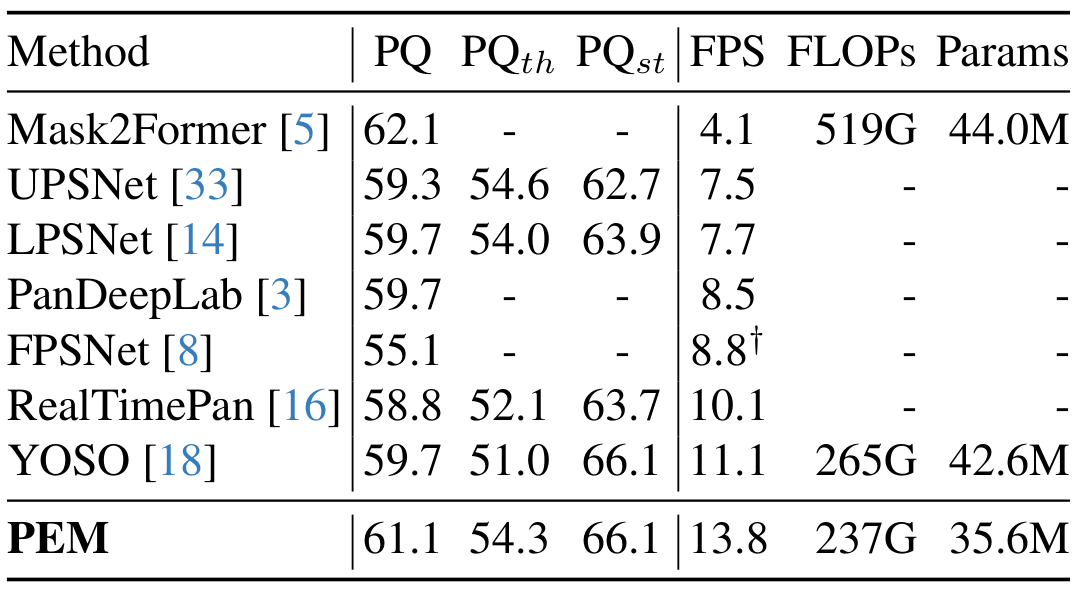
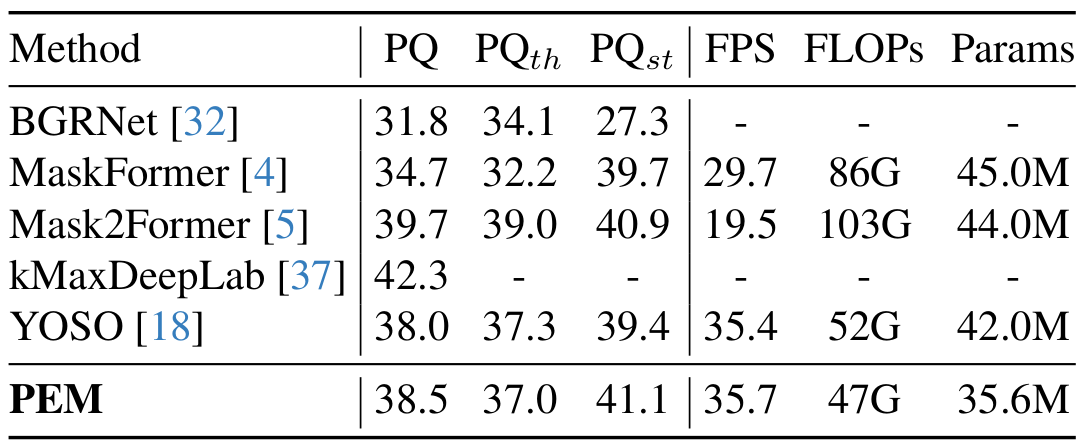
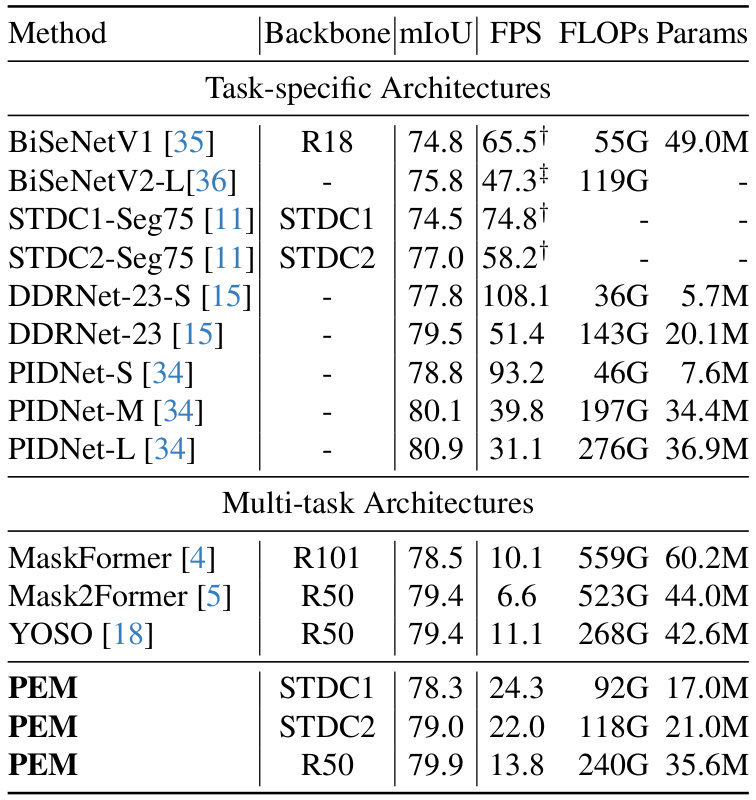
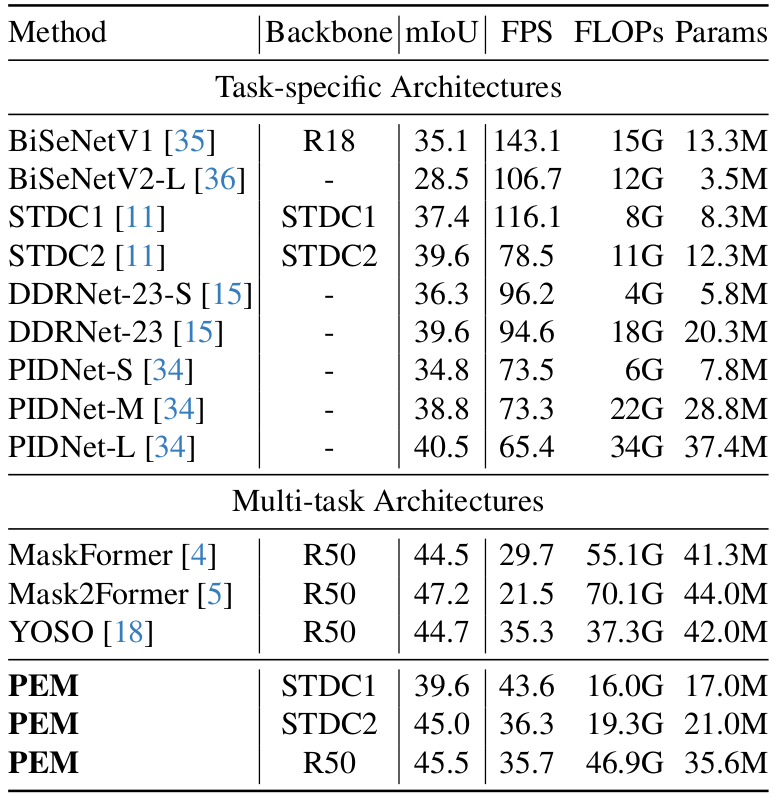
Recent transformer-based architectures have shown impressive results in the field of image segmentation. Thanks to their flexibility, they obtain outstanding performance in multiple segmentation tasks, such as semantic and panoptic, under a single unified framework. To achieve such impressive performance, these architectures employ intensive operations and require substantial computational resources, which are often not available, especially on edge devices. To fill this gap, we propose Prototype-based Efficient MaskFormer (PEM), an efficient transformer-based architecture that can operate in multiple segmentation tasks. PEM proposes a novel prototype-based cross-attention which leverages the redundancy of visual features to restrict the computation and improve the efficiency without harming the performance. In addition, PEM introduces an efficient multi-scale feature pyramid network, capable of extracting features that have high semantic content in an efficient way, thanks to the combination of deformable convolutions and context-based self-modulation. We benchmark the proposed PEM architecture on two tasks, semantic and panoptic segmentation, evaluated on two different datasets, Cityscapes and ADE20K. PEM demonstrates outstanding performance on every task and dataset, outperforming task-specific architectures while being comparable and even better than computationally-expensive baselines.
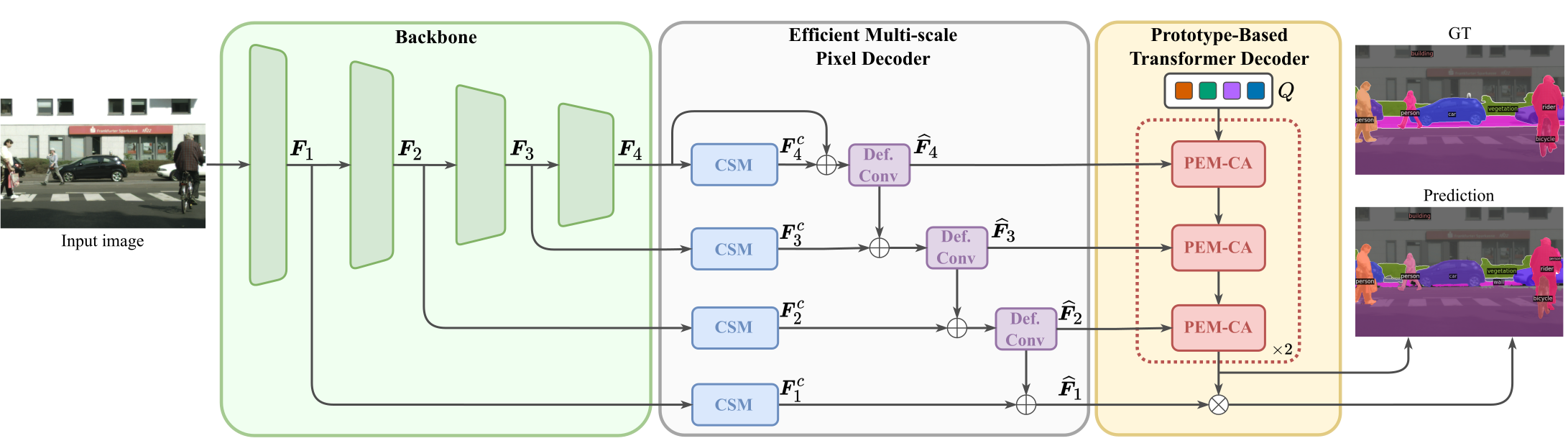
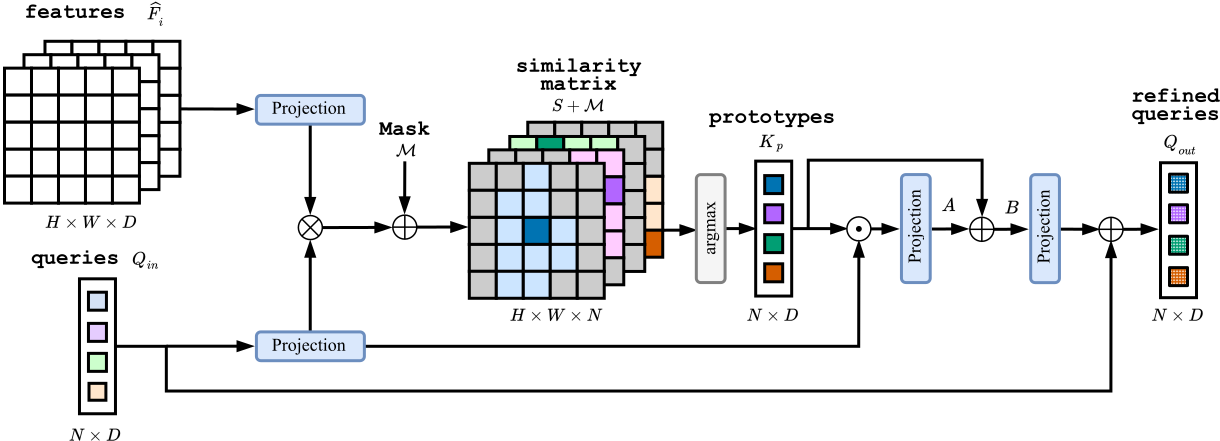
The core component of PEM is our novel Prototype-based Masked Cross-Attention (PEM-CA).
PEM-CA is an more efficient alternative to standard cross-attention operation in image segmentation.
Two main enhancements are introduced in PEM-CA:
The pixel decoder covers a fundamental role in extracting multi-scale features which allow a precise segmentation of the objects.
Mask2Former implements it as a feature pyramid network (FPN) enhanced with deformable attention.
However, ssing deformable attention upon an FPN introduces a computation overhead that makes the pixel decoder inefficient and unsuitable for real-world applications.
To maintain the performance while being computationally efficient, we use a fully convolutional FPN where we restore the benefits of deformable attention
by leveraging two key techniques.
First, to reintroduce the global context (i) and the dynamic weights (ii), we implement context-based self-modulation (CSM) modules that
adjust the input channels using a global scene representation. Moreover, to enable deformability (iii), we adopt deformable convolutions
that focus on relevant regions of the image by dynamically adapt the receptive field. This dual approach yields competitive performance while
preserving the computational efficiency.
@article{cavagnero2024pem,
title = {PEM: Prototype-based Efficient MaskFormer for Image Segmentation},
author = {Cavagnero, Niccol{\`o} and Rosi, Gabriele and Cuttano, Claudia and
Pistilli, Francesca and Ciccone, Marco and Averta, Giuseppe and Cermelli, Fabio},
journal = {CVPR},
year = {2024}
}This website is adapted from Nerfies, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License